KindleをPDF・テキストに
変換するChrome拡張
Kindle Cloud Readerで購入済みの本を、高精度にテキスト化してPDF・テキストファイルとして書き出せます。読書ノート、NotebookLMやChatGPTでの学習資料としても活用できます。
デモ動画
高精度な日本語テキスト変換
縦書き・横書きどちらにも対応。日本語・英語の活字を高い精度でテキスト化します。
かんたん操作
Kindle Cloud Readerで本を開き、拡張のボタンを押すだけ。自動でページをめくりながらテキストを抽出します。
複数フォーマット出力
テキスト・PDFをZIPファイルとしてまとめてダウンロード。用途に合わせて使えます。
見開きページ対応
見開き表示のページも自動で分割して処理。ページ順を保ったまま正確にテキスト化します。
料金
月10冊・各1,000ページまで利用可能。メール認証後、Chrome拡張内からサブスクリプション登録できます。
無料でも月20冊・各3ページまでお試しいただけます。まずは気軽にインストールしてみてください。
AI読書ガイド・事例集
Kindle本をNotebookLMやChatGPTに入れて、読書メモ、要約、音声解説、動画解説、スライド資料に広げるためのガイドと実例です。
Kindle本をNotebookLMで要約・質問する方法
Kindle本をNotebookLMに入れた後、読書メモ・テーマ質問・音声概要としてどう使えるかをまとめています。
Kindle本をChatGPTに読ませる方法
Kindle本をTXT化して、要約だけで終わらない読書メモや仕事への転用に使う方法をまとめています。
Kindleのハイライトだけでは足りない理由
ハイライトは断片、本の価値は文脈。AI読書に必要な本文テキスト化の考え方をまとめています。
『人間失格』をNotebookLMに入れたAI読書事例
YouTube動画、Spotify音声、NotebookLM実画面で見るAI読書事例です。
『ドグラ・マグラ』をNotebookLMに入れたAI読書事例
動画解説、音声解説、スライド資料まで作れた実例を、実際のNotebookLM画面つきで紹介します。
『人間椅子』をNotebookLMに入れたAI読書事例
短編怪奇を、動画解説・音声解説・スライド資料に変えた実例をNotebookLM画面つきで紹介します。
『桜の森の満開の下』をNotebookLMに入れたAI読書事例
満開の桜の美しさと怖さを、動画解説・音声解説・スライド資料に変えた実例です。
『注文の多い料理店』をNotebookLMに入れたAI読書事例
山猫軒の不穏さを、読前動画・音声解説・スライド資料に変えた実例です。
『銀河鉄道の夜』をNotebookLMに入れたAI読書事例
星空の旅を、動画解説・音声解説・スライド資料に変えた実例です。
『羅生門』をNotebookLMで読むAI読書プレビュー
門の下の一瞬を、横長動画・ショート動画・音声で読前にも読後にも戻れる入口にします。
『こころ』をNotebookLMで読むAI読書プレビュー
先生の沈黙と関係性を、動画・音声・問いとして整理する事例です。
『蜘蛛の糸』をNotebookLMで読むAI読書プレビュー
一本の糸が持つ問いを、短い動画と音声で見せるAI読書プレビューです。
『走れメロス』をNotebookLMで読むAI読書プレビュー
約束、走る時間、待つ友を、読前・読後に使える動画と音声の入口にします。
使い方
Chrome Web Storeからインストール
下のボタンをクリックしてBookHaloのストアページを開き、「Chromeに追加」をクリックするだけでインストール完了です。
Chrome Web Storeで開く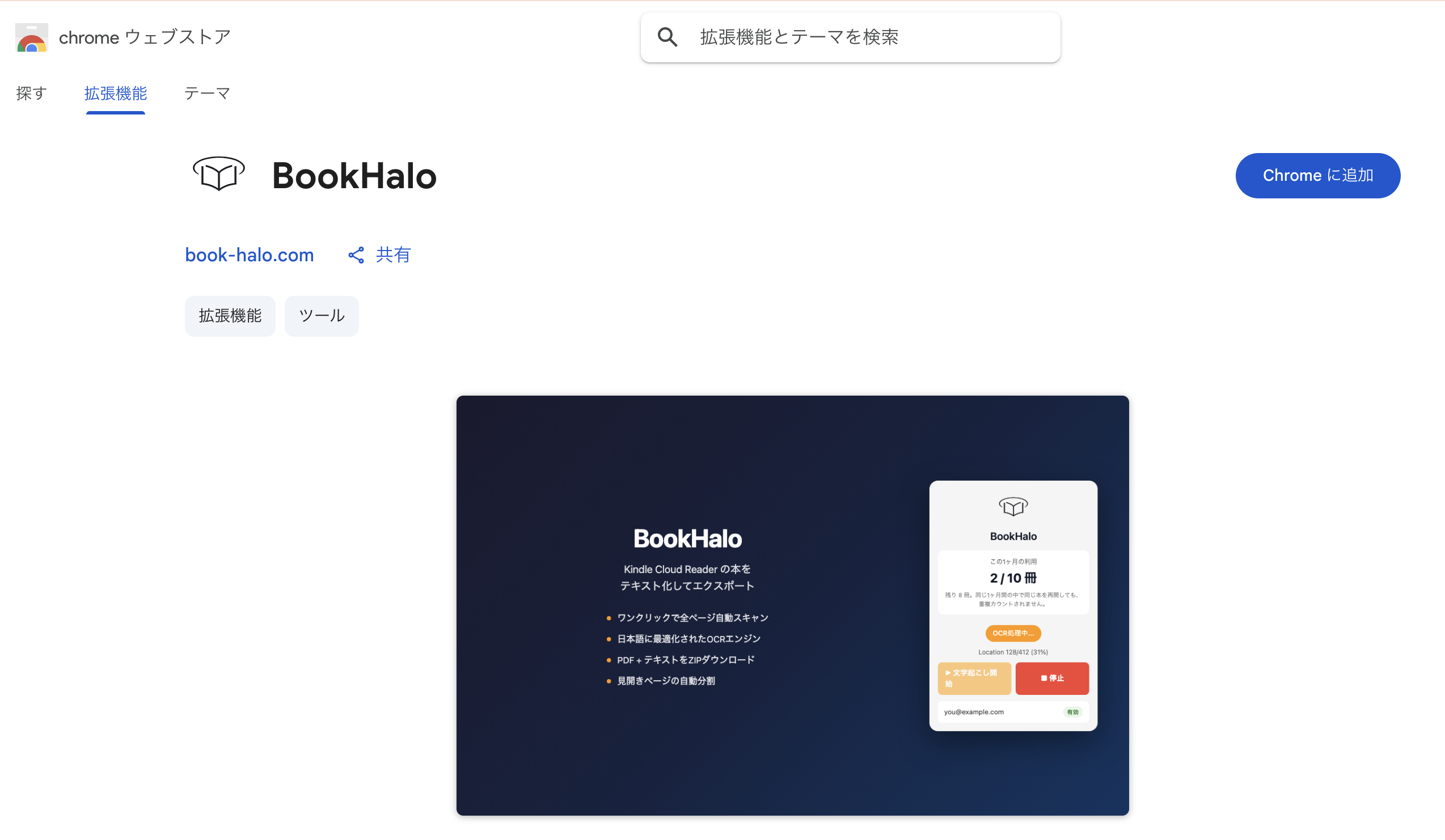
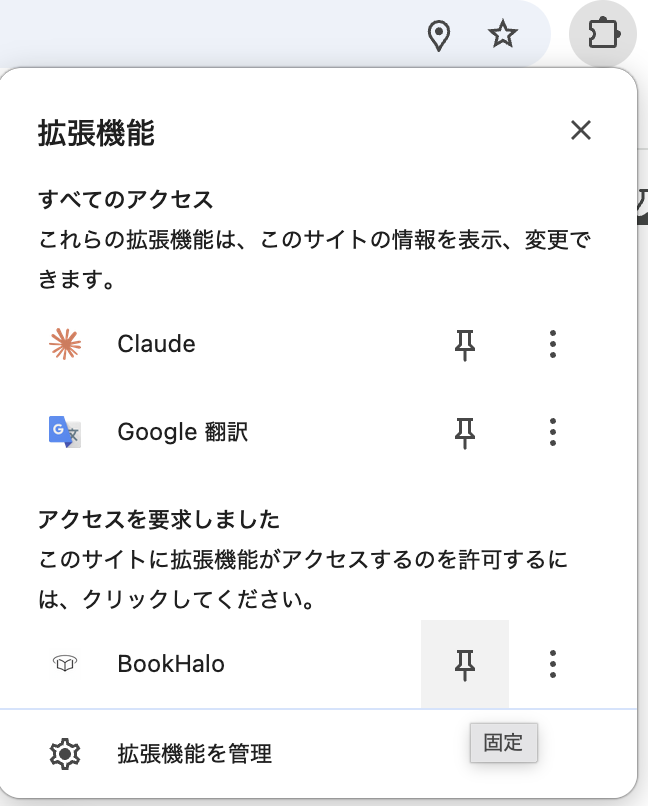
拡張機能をピン留めする
Chromeのツールバー右上のパズルアイコンをクリックし、BookHaloの横のピンアイコンをクリックして固定します。これでいつでもワンクリックで起動できます。
Kindle Cloud Readerで本を開く
ブラウザで read.amazon.co.jp または read.amazon.com などのKindle Cloud Readerにアクセスし、テキスト化したい本を開きます。Kindleアプリではなく、ブラウザ版で開いてください。
メールアドレスで登録・ログイン
BookHaloのアイコンをクリックしてポップアップを開き、メールアドレスを入力して認証コードでログインします。

「文字起こし開始」で自動処理
ボタンを押すと、現在のページから自動でページ送り・スクリーンショット・テキスト抽出が進みます。処理完了後、テキスト・PDFをまとめたZIPファイルが自動でダウンロードされます。

完成したZIPをダウンロード・確認する
全ページの処理が完了すると、結果がZIPファイルとして自動ダウンロードされます。
ダウンロードされるファイル:
- ブラウザ下部のダウンロードバー、または「ダウンロード」フォルダに 「書籍タイトル.zip」 が保存されます
- ZIPを右クリック →「すべて展開」で解凍してください(Macはダブルクリック)
フォルダの中身:
- full_text.txt ― 抽出した全文テキスト
- book.pdf ― 全ページをまとめたPDF
テキストファイルはそのままNotebookLMやChatGPTにアップロードして活用できます。
ご利用上の注意
- 処理中は他のタブやウィンドウを操作しないでください。スクリーンショットの撮影に影響します。
- Kindleのサンプル配布版には対応していません。
- デスクトップ版のGoogle Chrome(またはChrome系ブラウザ)が必要です。
利用規約・免責事項
- 個人利用に限ります。エクスポートしたデータの商用利用・再配布・転売は固く禁止します。
- 悪用厳禁。著作権者の権利を侵害する目的での使用は禁止です。本ツールはご自身が購入した書籍の個人的なバックアップ・学習目的のみにご使用ください。
- 本ツールの利用により生じたいかなる損害についても、開発者は一切の責任を負いません。
- ご利用にあたっては、Amazonの利用規約および各国の著作権法を遵守してください。